

Despite significant investment in generative AI (GenAI), many companies are still struggling to use it effectively. Inaccurate output, a lack of context, and inconsistent wording are just some of the challenges regularly faced. In this article you'll discover how your structured terminology database can be used to massively increase the precision and efficiency of your AI output through terminology-augmented generation (TAG) and the Quickterm MCP server.
Key Takeaways
- Key Takeaways
- GenAI: from hype to market maturity
- Why AI projects fail: current efficiency problems
- But why is this?
- The solution: terminology, TAG & MCP
- Unlock the terminology treasure chest!
- The four pillars of terminology-augmented generation (TAG)
- Terminology-augmented generation (TAG) in Quickterm
- Example TAG use cases
- How can I connect TAG to an LLM or an AI application?
- What is the Model Context Protocol (MCP)?
- How does the Quickterm MCP server for TAG work?
- What are the advantages of TAG via MCP?
- So what's the best way to get TAG with MCP installed at your company?
- Conclusion: TAG und MCP are real game changers
- (*) Further reading and studies:
GenAI: from hype to market maturity
Gartner's Hype Cycle is an illustrative model that describes the different phases of public awareness of a new technology when it is first introduced. In 2025, GenAI and its productive application by businesses exceeded the peak of inflated expectations in Gartner's Hype Cycle. After the hype typically comes a descent into the "trough of disillusionment" – which is exactly where GenAI currently finds itself in the public eye. But in the background, the first productive successes are beginning to emerge – and in some cases, the ascent to the "plateau of productivity" (which Gartner believes generative AI will reach in 2–5 years) is already underway.
If the forecasts are correct, we will probably see the first market-ready applications as early as 2027, not least due to trends such as explainable AI, robust AI, and, of course, terminology-augmented generation (TAG).
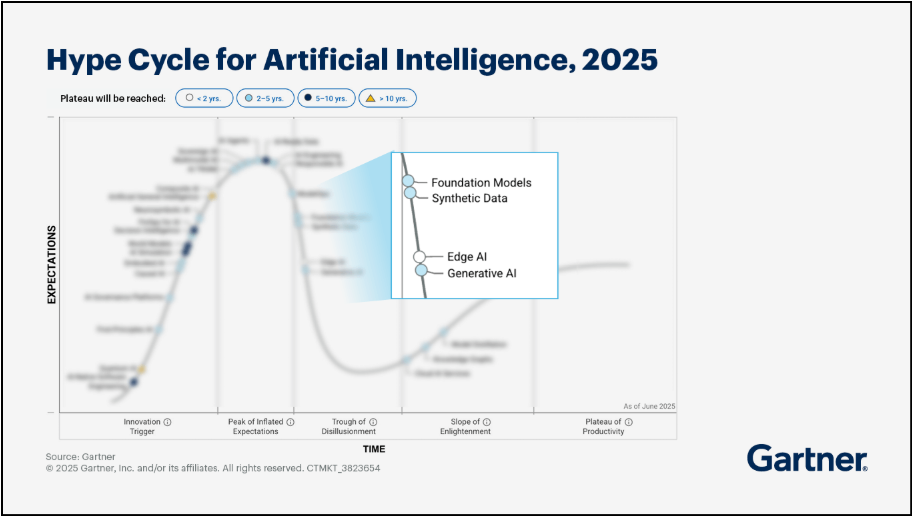
Source: https://www.gartner.com/en/articles/hype-cycle-for-artificial-intelligence-pc1)
Why AI projects fail: current efficiency problems
But first let's get back to the "trough of disillusionment". There remains a large discrepancy between the investment costs and the ROI:
- McKinsey: Over 90% of companies will invest more in AI in the next three years, but only 1% think that these investments are already bearing fruit.
- Deloitte: Only one third of all GenAI experiments make it to productive use.
- Boston Consulting Group: Nearly 75% of companies are struggling to realize and scale real value from AI.
But why is this?
In my blog post from May 2025 on "Terminology Augmented Generation (TAG): The Ideal Guardrail for Reliable GenAI", I analyzed and highlighted the following weaknesses:
- Precision and accuracy of GenAI output: Models tend to hallucinate in the absence of context. Explainable AI is not yet at the stage where we can rely on the generated content.
- Lack of corporate language: Since models are trained with global data, they do not know your company's specific corporate language.
- Inconsistency: The lack of consistency and uniformity of generated content is also very disruptive, especially in translations but of course also in the source context.
The solution: terminology, TAG & MCP
Terminology addresses precisely these weak points of LLM-generated content. With its clean concepts, terms, definitions, and other important metadata, it forms the solid conceptual basis for massively improving the three challenges of GenAI mentioned above.
What is terminology-augmented generation (TAG)?
With our terminology-augmented generation (TAG) approach, we can provide LLMs with relevant context in a highly precise and compact form. This context provides additional information to the LLM in order to enrich the output on the basis of specific data – in our case, terminology data such as definitions and usage notes. And with TAG and MCP, we can even do this in real time. Both our own research and studies by independent experts (*) have shown how effective terminology can be in improving GenAI quality:
- Increase in terminology fidelity in translations from 63% to 95% (see: Lackner, Vega-Wilson, Lang)
- Resolution of "edge cases": For example homonyms (words with several meanings) in translations can be solved with TAG with just a little additional information. All it takes is a small note and the LLM resolves ambiguous terms entirely on its own (disambiguation).
- Prevention of hallucinations: Even in applications such as chatbots or content creation, adding small pieces of additional information from the termbase solves problems such as hallucination when unknown concepts are encountered. It can also prevent misinformation from being given by a chatbot if incorrect terminology in the user's query means the desired solution is not found in the databases.
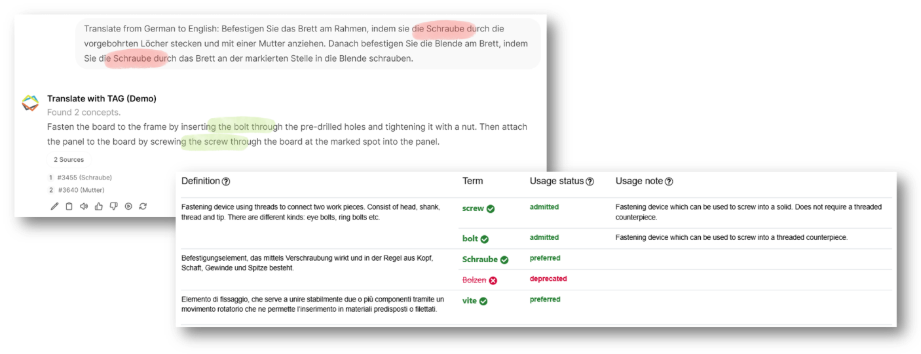
Example of the effectiveness of TAG: the small additional piece of information from the usage note of the termbase means that the LLM can correctly render the word "Schraube" in English as "bolt" or "screw". Without TAG, this disambiguation would not be possible and would require human correction loops.
Unlock the terminology treasure chest!
TAG is a classic example of Amara's Law, which states: "We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run". The short-term increase in productivity of GenAI was obviously dramatically overestimated, but the effect of terminology on the long-term success of GenAI is still being massively underestimated today. Terminology often already exists in most organizations, but it leads a solitary existence siloed away in the technical documentation or translation departments. It's high time that we unlock these data treasure chests for the benefit of the entire company: and for that we need TAG with MCP.
The four pillars of terminology-augmented generation (TAG)
I've already explained the actual use of terminology in augmenting GenAI output in my blog article on TAG. As a reminder, it is based on four pillars:
- Granular data structure: Termbases are precision repositories that allow the correct content to be read with pinpoint accuracy.
- Linguistic search: Over the last 30 years, termbase technology has been developed to support extremely reliable search methods that we can utilize for these applications.
- Optimized output formats: LLMs require contexts that are as compact and easily structured as possible and in language that is as natural as possible. And how do we create these formats? Using TAG, of course.
- Real-time access: Instead of slow vector searches in static data, TAG accesses data in real time via our special retrieval API, which is designed for speed due to the requirements of translators, content creators, and big data.
Terminology-augmented generation (TAG) in Quickterm
These four basic principles of TAG can be configured in Quickterm using "retrieval profiles". By configuring the search logic and output directly in Quickterm, terminology managers can customize TAG to their exact requirements. After all, each potential use case for TAG requires a different approach.
Example TAG use cases
- Translation: For this use case, we need the terms as well as any additional information on usage, definition, and, in cases of doubt, grammatical information.
- Term verification: The forbidden and permitted terms are particularly relevant for this task, plus any additional information on usage or meaning.
- Classic terminology search: For queries about the meaning of concepts, we mainly need information such as definitions, example sentences, and perhaps also subject areas or departmental information.
- Search for related concepts: In some use cases, we want to enrich a prompt with keywords or related terms, such as when creating content or using chatbots that access knowledge data. Here it is also useful to use concept maps or the other possible links in Quickterm to output related concepts from the termbase that do not actually appear in the query itself.
Since terminology managers know the content and purpose of the termbase structure better than anyone, it makes sense that they should define these applications and set them up accordingly in Quickterm. These configurations are created in Quickterm as "retrieval profiles" and made available for TAG functions.
All the AI manager or IT department then has to do is integrate the TAG retrievals into the AI applications. But how does this work in practice?
How can I connect TAG to an LLM or an AI application?
There are basically several ways of incorporating TAG into your AI workflows, each with their own advantages and disadvantages:
Programming
Firstly, it is possible to program hard-coded pipelines or function calls directly in individual AI environments and to address the TAG functionality of Quickterm via the configured retrieval endpoints of the Quickterm API. This is the most reliable, but by far the most time-consuming form of implementation, as the IT department basically has to plan, program, and maintain these pipelines for every use case and every application.
Function calling
Many LLM applications offer "function calling". This is where corporate IT departments can develop "functions" that enable LLMs to execute certain external prompts independently. For example, a "Find translations" function could be developed that receives a TAG output via the Quickterm API and the retrieval endpoints, and automatically adds this to the prompt (augmentation). This means that new pipelines no longer have to be developed for every application. However, these functions must also be developed and maintained by your IT department, and they are implemented differently for each LLM.
Model Context Protocol (MCP)
The game changer when it comes to connecting external sources to LLMs is the Model Context Protocol (MCP). An MCP server is able to provide ready-made functions (or "tools", as MCP calls them) and inform the LLM when these tools should be called. As a result vendors such as Kaleidoscope can supply customers with defined use cases as off-the-shelf solutions and a single MCP server can be used for all AI applications in an organization. This means a massive reduction in the burden on the company's IT department and the software vendor's experience can be used for the benefit of different end customers.
What is the Model Context Protocol (MCP)?
MCP is a standardized exchange protocol that allows models to automatically search and use external sources to augment the knowledge and effectiveness of models as well as to refine the output. Put simply, it is a protocol that gives context to the model. The protocol was developed and published as open source in 2024 by Anthropic (anthropic.com), the developers behind the LLM Claude. General information on MCP can be found at https://modelcontextprotocol.io.
In short, MCP is a standardized interface for connecting LLMs to any external databases, repositories, or APIs. In contrast to function calling, not every company application has to be connected separately to every conceivable LLM. Instead the MCP server acts as a kind of centralized hub offering standardized, cross-tool access for both LLMs and external software.
This makes it possible for the first time for vendors such as Kaleidoscope to provide preconfigured off-the-shelf functionalities independently of the LLMs or AI applications used by the customer.
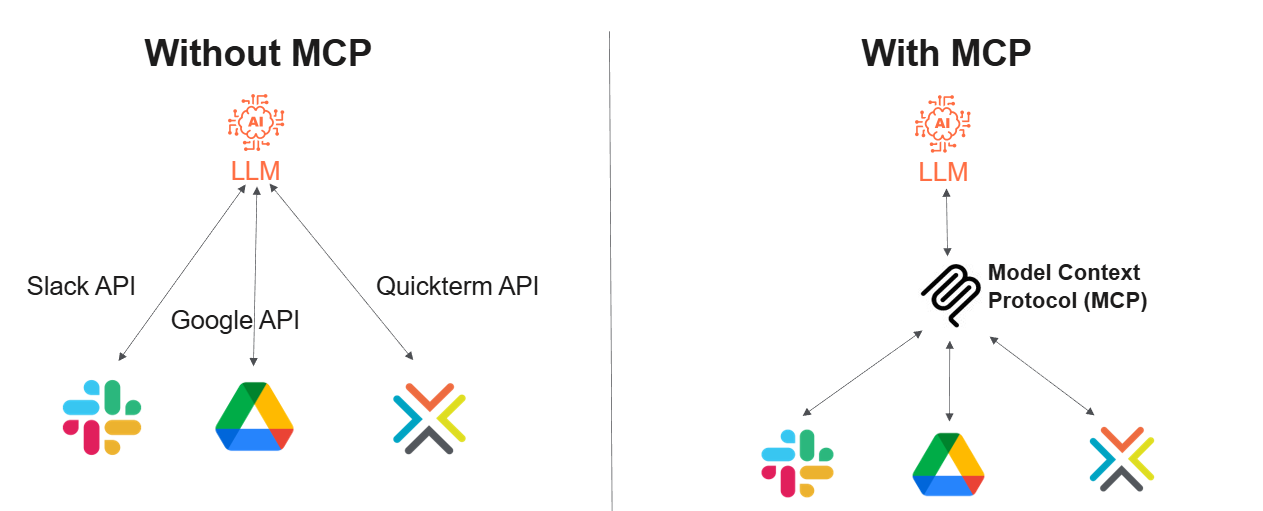
Inspired by: What Is the Model Context Protocol (MCP) and How It Works
How does the Quickterm MCP server for TAG work?
The Quickterm MCP server currently offers four configurable functions:
- Terminology Details: Classic terminology search and output of hits including other relevant data
- Check Terminology: Terminology check of a text and output of the permitted variants plus other configured information
- Find Translation: Search for terminology in a text and output of the foreign-language equivalents including defined additional information
- Related Terminology: Search for similar concepts, also via the concept maps (!), and output of related concepts plus metadata by configuration
A retrieval profile is stored in Quickterm for each of these tools, in which the terminology managers have configured the exact function (search, analysis, etc.) and the data to be supplied (languages, fields, format). This retrieval profile is essentially how we integrate the TAG principle into Quickterm, as explained in more detail in my blog post from May 2025.
Only two pieces of information are required for the configuration in the respective LLM application:
- The URL of the MCP server (which with Quickterm is the respective Quickterm URL plus the suffix "/mcp").
- The authentication. Any number of "MCP users" can be configured in Quickterm, each of which has their own authentication tokens or will soon be able to authenticate themselves via OAuth2. This also makes it possible to configure different scenarios or even "personal" MCP profiles. The Quickterm MCP server can be accessed via different tokens (=users) with the relevant configuration for different use cases.
If the user now enters a prompt in the AI application that requires a terminology definition or a translation, for example, then the model either looks up the functions in the MCP server all by itself (depending on the vendor and configuration) or it must be prompted to do so by incorporating a trigger in the prompt or even permanently in the wizard.
The MCP server in turn forwards the data to the retrieval endpoint of the Quickterm API. Quickterm then performs the search or text analysis and returns exactly the data in the desired format as configured in the retrieval profile. This optimized result is returned to the LLM, which can now use this extra contextual information to generate a better response. And voilà, that's TAG in action!
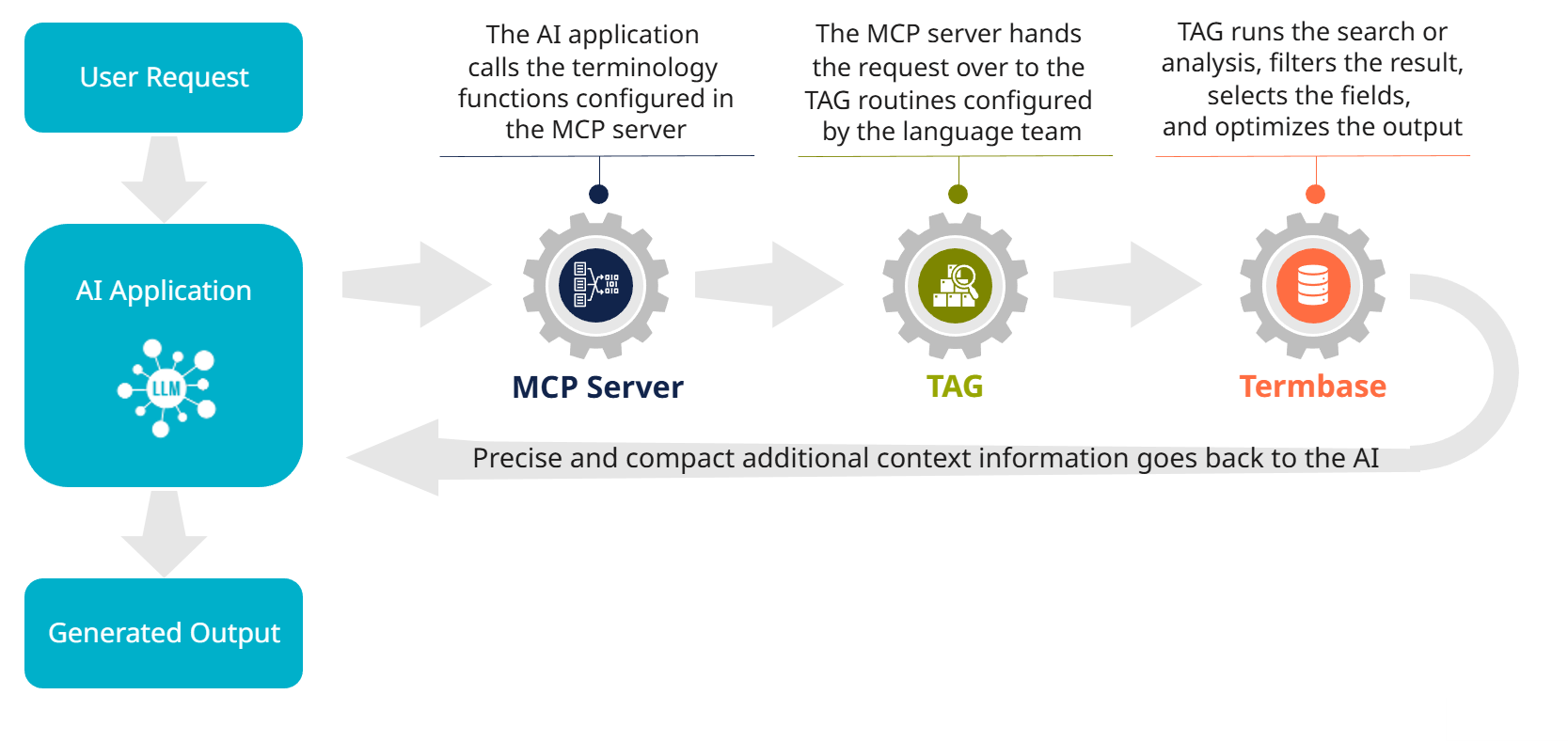
Terminology-generated augmentation process in Quickterm
As an illustrative example, here is a video showing how the Quickterm MCP server is connected in Langdock.
What are the advantages of TAG via MCP?
Terminology-augmented generation alone offers numerous advantages over classic RAG or even pure prompt engineering:
- It requires significantly fewer tokens than RAG, which not only makes processing faster and more cost-effective, but also increases the accuracy of the model thanks to the extra contextual information. Too many tokens often overwhelm a model, causing it to "overlook" the instructions it's been given.
- The results are more precise because the exact field contents that the AI actually needs can be transferred instead of "probably relevant" content chunks. In addition, it is also possible to limit which data should be searched for and how (filter), as well as which data should be output.
- By accessing relevant metadata, LLMs can also solve difficult edge cases, such as the disambiguation of homonyms in translation (see also the video above).
- The output format can be optimized for specific use cases. YAML has proven to be an effective format for LLMs in our current research, which is why our MCP server passes YAML to the LLMs.
- Access is in real time and not to static, uploaded data.
- The entire configuration can be carried out by the terminology or language department, which enables interdisciplinary collaboration and an efficient division of labor.
In addition, the connection via Quickterm MCP server significantly simplifies the implementation of TAG:
- The company IT department does not have to program its own clients. With other approaches such as function calling or pipelines, a new client has to be developed for each tool to be connected. With MCP, a standard has been created that can be used for all use cases and applications.
- The LLM naturally calls the correct MCP tool. This is linked to a retrieval profile in Quickterm, which in turn controls the search, output data, output format, and more. Only the contexts that the LLM actually requires in the respective use case are returned.
- TAG with MCP enables an extremely efficient implementation of TAG. Since the language team can configure the TAG functions at a linguistic level, IT only has to connect the MCP server with the URL and authentication token.
So what's the best way to get TAG with MCP installed at your company?
If you are not yet in contact with your internal IT department regarding terminology for AI and (terminology) augmented generation or fine-tuning of LLMs with terminology data, we recommend that all terminology managers ask around and find the right contacts. AI projects are often very decentralized or cross-functional and project managers are not even aware of the potential terminology that exists, not to mention the immensely valuable, structured, coordinated, and multilingual language data at their disposal.
The most important thing your internal AI projects need is reliable and structured data about the company's products, processes, and other relevant information. And it is precisely this information that is available in the termbase in the form of concepts or terms. In most cases, the advantage of TAG is also easy to explain to an AI project manager (and of course you can cite the benefits mentioned in this blog!). AI developers are also extremely happy that all they have to do is integrate a ready-made approach provided for them in the MCP server for Quickterm.
The AI department saves a massive amount of implementation work with MCP and achieves its goal significantly faster and with greater success. What's more, you and your terminology team or language department are responsible for the actual configuration of the TAG functions. So why wouldn't the project management team want to talk to you?
If you would like to learn more or refresh your knowledge of AI before these discussions, we offer customized public or in-house workshops. In just a few hours, we will get you up to speed with TAG, RAG, and prompting, and explain why terminology is so helpful in corporate AI.
In addition, we also offer a TAG Discovery Workshop and are happy to take part in your first internal discussions.
Conclusion: TAG und MCP are real game changers
From our point of view, TAG via MCP is a real game changer. This technology enables language experts to make our valuable terminology database accessible to the entire company in no time at all – transparently integrated in the background in all conceivable AI applications. Terminology thus becomes a central asset of the organization, which not only helps the standing of terminology as a concept within the company, but also brings a significantly higher return on investment for the terminology business model.
And, of course, TAG via MCP takes corporate AI a considerable step further in terms of reliability and productivity. All in keeping with our mission to transform terminology into the catalyst for maximum productivity in your business.
(*) Further reading and studies:
- Klaus Fleischmann, Christian Lang (2025): Terminologie in der KI. Wie mit Terminologie der Output von LLMs und GenAI optimiert werden kann
- Anna Lackner, Alena Vega-Wilson and Christian Lang: Terminology Augmented Generation: A Systematic Review of Terminology Formats for In-Context Learning in LLMs
- Giorgio Maria Di Nunzio: Terminology-Augmented Generation (TAG): Foundations, Use Cases, and Evaluation Paths
- Karolina Suchowolec: TermRAG, TAG & Co. – viele Namen, vielfältige Einsatzmöglichkeiten
