

Trotz erheblicher Investitionen in generative KI (GenAI) kämpfen viele Unternehmen noch immer mit der effektiven Nutzung. Ungenauer Output, fehlender Kontext und inkonsistente Kommunikation sind die Herausforderungen. Dieser Artikel zeigt, wie Sie durch Terminology-Augmented Generation (TAG) und den Quickterm MCP-Server Ihre Terminologie als strukturierte Wissensbasis nutzen, um Präzision und Effizienz Ihrer KI massiv zu steigern.
Key Takeaways
- Key Takeaways
- GenAI: Vom Hype zur Marktreife
- Warum KI-Projekte scheitern: Aktuelle Effizienzprobleme
- Doch was sind die Gründe dafür?
- Die Lösung: Terminologie, TAG & MCP
- Hebt die Datenschätze!
- Die vier Säulen von Terminology-Augmented Generation (TAG)
- Terminology-Augmented Generation (TAG) in Quickterm
- Beispiele für TAG Use Cases
- Wie kann ich TAG an ein LLM oder eine KI-Anwendung anbinden?
- Was ist das Model Context Protocol (MCP)?
- Wie funktioniert der Quickterm MCP-Server für TAG?
- Welchen Vorteil hat TAG via MCP?
- Wie können Sie das angehen?
- Fazit: TAG und MCP sind echte Gamechanger
- Weiterführende Literatur und Studien
GenAI: Vom Hype zur Marktreife
Der Hype Cycle von Gartner ist ein anschauliches Modell, das die Phasen der öffentlichen Aufmerksamkeit einer neuen Technologie bei deren Einführung beschreibt. 2025 überschritt GenAI und deren produktive Anwendung in Unternehmen den Gipfel der überzogenen Erwartungen im Hype Cycle von Gartner. Nach dem Hype folgt typischerweise der Abstieg in das "Tal der Enttäuschung". Genau an dieser Stelle befindet sich aktuell GenAI in der öffentlichen Wahrnehmung. Aber im Hintergrund beginnen sich die ersten produktiven Erfolge abzuzeichnen, und es beginnt teilweise bereits der Aufstieg zum "Plateau der Produktivität", den die generative KI laut Gartner in 2-5 Jahren erreichen wird.
Treffen die Prognosen zu, erleben wir vermutlich also bereits 2027 die ersten marktreifen Anwendungen, nicht zuletzt auch durch Trends wie Explainable AI, robuste KI und natürlich auch Terminology-Augmented Generation (TAG).
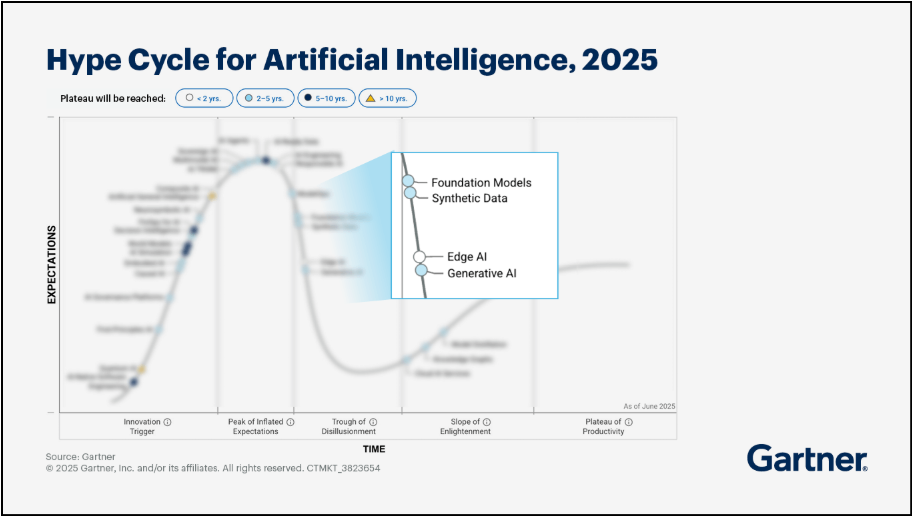
Quelle: https://www.gartner.com/en/articles/hype-cycle-for-artificial-intelligence-pc1)
Warum KI-Projekte scheitern: Aktuelle Effizienzprobleme
Aber zuerst zurück zum "Tal der Enttäuschung". Die Diskrepanz zwischen Investition und Ertrag ist aktuell noch groß:
- McKinsey: 92% der Unternehmen werden in den nächsten 3 Jahren mehr in KI investieren, aber nur 1% denkt, dass diese Investitionen bereits Früchte tragen.
- Deloitte: Nur ein Drittel aller GenAI-Experimente schafft es bis zum produktiven Einsatz.
- Boston Consulting Group: BCG sagt, dass 74% aller Unternehmen damit kämpfen, tatsächlichen Nutzen aus KI zu erzielen und diesen zu skalieren.
Doch was sind die Gründe dafür?
Bereits in unserem Blogbeitrag von Mai 2025 zum Thema "Terminology-Augmented Generation (TAG): Die Leitplanke für den KI-Highway" haben wir folgende Schwachstellen analysiert und aufgezeigt:
- Präzision und Korrektheit von GenAI-Output: Modelle neigen bei fehlendem Kontext zur Halluzination. Explainable AI ist in der Entwicklung noch nicht so weit, dass wir uns auf generierte Inhalte verlassen können.
- Fehlende Unternehmenssprache: Da Modelle mit weltweiten Daten trainiert sind, kennen sie die spezifische Unternehmenssprache nicht.
- Inkonsistenz: Insbesondere in Übersetzungen, aber natürlich auch im Ausgangskontext sehr störend, ist auch die fehlende Durchgängigkeit und Einheitlichkeit von generiertem Inhalt.
Die Lösung: Terminologie, TAG & MCP
Genau bei diesen Schwachstellen von LLMs punktet Terminologie treffsicher: Mit ihren sauberen Konzepten, Benennungen, Definitionen und anderen wichtigen Metadaten bildet sie die solide begriffliche Basis, um die oben genannten drei Herausforderungen von GenAI bezüglich Korrektheit, Unternehmenssprache und Inkonsistenz massiv zu verbessern.
Was ist Terminology-Augmented Generation (TAG)?
Mit unserem Ansatz der Terminology-Augmented Generation (TAG) können wir LLMs relevanten Kontext, in höchst präziser und kompakter Form liefern. Dieser Kontext gibt Zusatzinformationen an das LLM, um den Output auf der Basis konkreter Daten anreichern zu können. In unserem Fall sind dies Terminologiedaten wie Definitionen, Verwendungshinweise etc. Und mit TAG und MCP können wir dies in Echtzeit. In unserer Forschung, aber auch in Studien anderer (*) zeigt sich, wie effektiv der Einsatz von Terminologie zur Verbesserung der GenAI-Qualität ist:
- Steigerung der Terminologie-Treue in Übersetzungen von 63% auf 95% (siehe: Lackner, Vega-Wilson, Lang)
- Lösung von "Edge Cases": z. B. Homonyme (Wörter mit mehreren Bedeutungen) in Übersetzungen können mit TAG mit nur wenigen Zusatzinformationen gelöst werden: Ein kleiner Zusatzhinweis und das LLM löst mehrdeutige Benennungen komplett selbständig auf (Desambiguierung).
- Halluzinationen vermeiden: Auch in Anwendungen wie Chatbots oder Content-Erstellung löst das Hinzufügen von kleinen Zusatzinformationen aus der Termbank Probleme wie Halluzination bei unbekannten Konzepten oder auch Fehlinformationen eines Chatbots, wenn falsche Terminologie bei Anfragen nicht zur gewünschten Lösung in den Datenbanken führen.
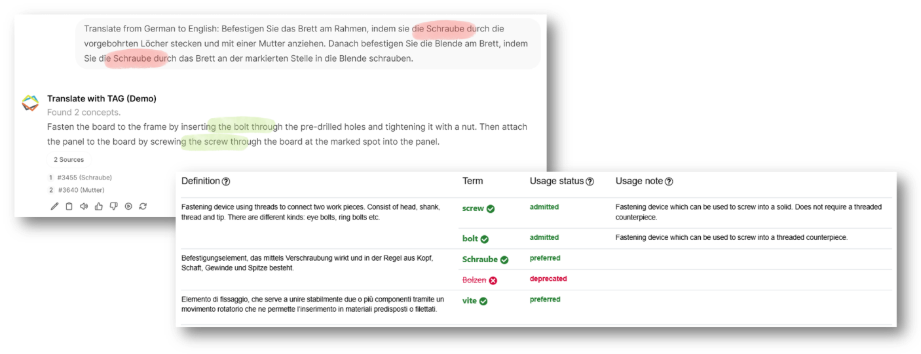
Beispiel für die Effektivität von TAG: die kleine Zusatzinformation aus der Usage Note der Termbank bewirkt, dass das LLM das Wort "Schraube" auf Englisch korrekt als "bolt" vs. "screw" wiedergeben kann. Ohne TAG ist diese Desambiguierung nicht möglich und bedingt humane Korrekturschleifen.
Hebt die Datenschätze!
TAG ist ein klassisches Beispiel von Amaras Gesetz, das besagt: "Wir neigen dazu, die kurzfristige Wirkung einer Technologie zu überschätzen und die langfristige Wirkung zu unterschätzen". Die kurzfristige Produktivitätssteigerung von GenAI wurde ganz offensichtlich dramatisch überschätzt, die Wirkung von Terminologie für den langfristigen Erfolg von GenAI wird aber aktuell noch massiv unterschätzt. Dabei existiert Terminologie oft bereits im Unternehmen, sie führt aber ein Einzeldasein in Abteilungen wie Technischer Dokumentation oder Übersetzung. Höchste Zeit, diese Datenschätze für das gesamte Unternehmen zu heben.
Und genau dafür gibt es TAG via MCP.
Die vier Säulen von Terminology-Augmented Generation (TAG)
Die eigentliche Verwendung von Terminologie zur Augmentierung von GenAI-Output haben wir bereits in unserem Blogartikel zu TAG erläutert. Sie beruht auf 4 Säulen:
- Granulare Datenstruktur: Termbanken sind äußerst präzise strukturiert, wodurch der korrekte Inhalt punktgenau ausgelesen werden kann.
- Linguistische Suche: Termbank-Technologien haben in den letzten 30 Jahren sehr zuverlässige Suchmethoden entwickelt, die wir uns für diese Anwendungen zunutze machen können.
- Optimierte Output-Formate: LLMs benötigen möglichst kompakte, leicht strukturierte Kontexte in möglichst natürlicher Sprache. Genau diese können wir mit TAG erzeugen.
- Echtzeitzugriff: Statt langsamer Vektor-Suche in statischen Daten erfolgt der Zugriff in Echtzeit über unsere spezielle Retrieval API, die aufgrund der Anforderungen aus Übersetzung, Content und Big Data auf Performanz ausgelegt sind.
Terminology-Augmented Generation (TAG) in Quickterm
Diese 4 Grundprinzipien von TAG sind in Quickterm über sogenannte "Retrieval Profile" konfigurierbar. Das bedeutet, dass Terminologieverantwortliche direkt in Quickterm die Suchlogik und den Output konfigurieren können. So kann TAG perfekt auf die jeweilige Anforderung abgestimmt werden. Denn natürlich ist es ein Unterschied, welchen Use Case wir mit TAG abbilden möchten.
Beispiele für TAG Use Cases
- Übersetzung: Für diesen Anwendungsfall benötigen wir die Benennungen sowie etwaige Zusatzinformationen zu Verwendung, Definition, in Zweifelsfällen auch Grammatikinformation.
- Termprüfung: Für diese Aufgabe sind insbesondere die verbotenen und erlaubten Benennungen relevant, plus etwaige Zusatzinformationen zur Verwendung oder Bedeutung.
- Klassische Terminologiesuche: Für Anfragen nach der Bedeutung von Konzepten benötigen wir hauptsächlich Informationen wie Definitionen, Beispielsätze und zusätzlich vielleicht Fachgebiete oder Abteilungsinformationen.
- Suche nach verwandten Konzepten: In manchen Use Cases möchte man einen Prompt um Schlagwörter oder verwandte Benennungen anreichern, beispielsweise bei der Content-Erstellung oder in Chatbots, die auf Wissensdaten zugreifen. Hier ist es auch sinnvoll, über Concept Maps, oder andere Verlinkungen in Quickterm, verwandte Konzepte aus der Termbank auszugeben, die in der Anfrage selbst eigentlich gar nicht vorkommen.
Da die Terminologieverantwortlichen den Inhalt und Zweck der Termbankstruktur am besten kennen, liegt es für uns auf der Hand, dass sie diese Anwendungen definieren und entsprechend in Quickterm einrichten. Diese Konfigurationen werden in Quickterm als "Retrieval-Profile" angelegt und TAG zur Verfügung gestellt.
Die KI-Zuständigen oder IT-Abteilungen müssen dann nur noch die TAG-Aufrufe in die KI-Anwendungen einbauen. Aber wie geht das?
Wie kann ich TAG an ein LLM oder eine KI-Anwendung anbinden?
Dafür gibt es grundsätzlich mehrere Möglichkeiten, jede mit ihren Vor- und Nachteilen:
Programmieren
Zunächst ist es möglich, hartcodierte Pipelines oder Funktionsaufrufe direkt in einzelnen KI-Umgebungen zu programmieren und die TAG-Funktionalität von Quickterm über die konfigurierten Retrieval Endpoints der Quickterm-API anzusprechen. Das ist die zuverlässigste, aber mit Abstand aufwändigste Form der Implementierung, da die Unternehmens-IT im Grunde für jeden Use Case und jede Applikation diese Pipelines planen, programmieren und warten muss.
Function Calling
Viele LLM-Anwendungen bieten daher ein sogenanntes "Function Calling". Die Unternehmens-IT kann "Funktionen" entwickeln, über die LLMs bestimmte externe Aufrufe selbständig ausführen können. Beispielsweise könnte eine Funktion "Find translations" entwickelt werden, die über die Quickterm API und die Retrieval Endpoints einen TAG-Output erhält und diesen selbständig dem Prompt hinzufügt (Augmentierung). Dadurch müssen nicht mehr in jeder Anwendung neue Pipelines entwickelt werden. Allerdings müssen auch diese Funktionen von Ihrer IT entwickelt und gewartet werden, und sie werden für jedes LLM unterschiedlich implementiert.
Model Context Protocol – MCP
Der Gamechanger in der Frage der Anbindung externer Quellen an LLMs lautet Model Context Protocol (MCP). Ein MCP-Server ist in der Lage, vorgefertigte Funktionen oder "Tools", wie MCP sie nennt, zur Verfügung zu stellen und das LLM zu informieren, wann dieses Tools aufgerufen werden sollen. Damit kann beispielsweise ein Hersteller wie Kaleidoscope definierte Use Cases out-of-the-box an Kunden ausliefern: Ein einziger MCP-Server kann dabei für sämtliche KI-Anwendungen im Unternehmen verwendet werden. Das bedeutet eine massive Entlastung der Unternehmens-IT und Nutzung der Erfahrungen des Herstellers mit unterschiedlichen Endkunden.
Was ist das Model Context Protocol (MCP)?
MCP ist ein standardisiertes Austauschprotokoll, mit dem Modelle externe Quellen automatisch durchsuchen und nutzen können, damit das Wissen und die Handlungsfähigkeit der Modelle augmentiert und der Output verfeinert werden kann. Daher auch der Name „Model Context Protocol“. Entwickelt und als Open Source veröffentlicht wurde das Protokoll 2024 von Anthropic (anthropic.com), dem Hersteller des LLMs Claude. Allgemeine Informationen zu MCP finden Sie unter https://modelcontextprotocol.io.
Kurz zusammengefasst bietet MCP eine standardisierte Schnittstelle zwischen LLMs und beliebigen externen Datenbanken, Repositories oder auch APIs. Im Gegensatz zu Function Calling muss daher nicht jede Unternehmensanwendung separat an jedes erdenkliche LLM angebunden werden, sondern der MCP-Server fungiert sozusagen als Hub. Er bietet sowohl in Richtung LLM als auch in Richtung externer Tools eine standardisierte, tool-übergreifende Schnittstelle.
Das macht es erstmals Herstellen wie beispielsweise Kaleidoscope möglich, vorkonfigurierte out-of-the-box Funktionalitäten unabhängig vom kundenseitig verwendeter LLMs oder KI-Anwendungen bereitzustellen.

Inspiriert von: What Is the Model Context Protocol (MCP) and How It Works
Wie funktioniert der Quickterm MCP-Server für TAG?
Der Quickterm MCP-Server bietet derzeit vier konfigurierbare Funktionen:
- Terminology Details: Klassische Terminologiesuche und Output der Treffer samt anderer relevanter Daten
- Check Terminology: Terminologieprüfung in einem Text und Output der erlaubten Varianten plus anderer konfigurierter Informationen
- Find Translation: Suche nach Terminologie in einem Text und Output der fremdsprachlichen Entsprechungen samt definierter Zusatzinfos
- Related Terminology: Suche nach ähnlichen Konzepten, auch über die Concept Maps (!), und Output von verwandten Konzepten plus Metadaten nach Konfiguration
Für jedes dieser Tools ist in Quickterm ein Retrieval-Profil hinterlegt, in dem die Terminologieverantwortlichen die genaue Funktion (Suche, Analyse etc.) sowie die zu liefernden Daten (Sprachen, Felder, Format) konfiguriert haben. Dieses Retrieval Profil ist im Grunde unsere Umsetzung des TAG-Prinzips in Quickterm, wie im Blogbeitrag von Mai 2025 genauer erläutert.
In der jeweiligen LLM-Anwendung werden nur zwei Informationen für die Konfiguration benötigt:
- Die URL des MCP-Servers: Bei Quickterm entspricht das der jeweiligen Quickterm-URL mit einem /mcp – Suffix.
- Die Authentifizierung: In Quickterm können beliebig viele "MCP-User" konfiguriert werden, die jeweils über eigene Authentifizierungs-Tokens verfügen oder sich demnächst auch über OAuth2 authentifizieren können. Damit ist es auch möglich, unterschiedliche Szenarien oder sogar „persönliche“ MCP-Profile zu konfigurieren: Der Quickterm MCP-Server kann über verschiedene Tokens (=User) mit der relevanten Konfiguration für unterschiedliche Use Cases aufgerufen werden.
Gibt nun der Benutzer in der KI-Anwendung einen Prompt ein, der z. B. eine Terminologie-Definition oder eine Übersetzung erfordert oder weitere Benennungen ergänzen soll, dann schlägt das Modell je nach Hersteller und Konfiguration entweder ganz von sich aus die Funktionen im MCP-Server nach, oder es muss dazu veranlasst werden, indem ein Trigger in den Prompt oder auch fix in den Assistenten eingebaut wird.
Der MCP-Server wiederum gibt die Daten weiter an den Retrieval-Endpunkt der Quickterm API. Quickterm führt dann die Suche oder Textanalyse durch und retourniert exakt die Daten im gewünschten Format, wie das im Retrieval Profil konfiguriert ist. Dieses optimierte Resultat wird wieder an das LLM zurückgegeben, das mithilfe dieses Kontexts nun einen besseren Output generieren kann. Voilà, das ist TAG in Action!
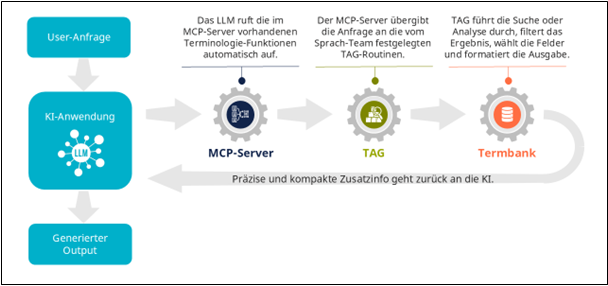
Ablauf von Terminology Generated Augmentation in Quickterm
Als anschauliches Beispiel entdecken Sie ein Video, das die Anbindung des Quickterm MCP-Servers beispielhaft in Langdock zeigt:
Welchen Vorteil hat TAG via MCP?
Terminology-Augmented Generation bietet schon alleine zahlreiche Vorteile gegenüber klassischem RAG oder auch reinem Prompt Engineering:
- Es benötigt deutlich weniger Tokens als beispielsweise RAG, wodurch die Verarbeitung nicht nur schneller und kostengünstiger ist, sondern auch die Genauigkeit des Modells bei der Befolgung des Kontexts steigt. Zu viele Tokens überfordern oft ein Modell, es tendiert dazu, die Anweisungen in der Mitte zu "übersehen".
- Die Ergebnisse sind präziser, da die genauen Feldinhalte übergeben werden können, statt "wahrscheinlich relevanten" Content-Chunks. Darüber hinaus kann auch eingegrenzt werden, in welchen Daten wie gesucht werden soll (Filter), und welche Daten ausgegeben werden sollen.
- Durch die Ausgabe relevanter Metadaten können LLMs auch schwierige Edge Cases lösen, wie beispielsweise das Desambiguieren von Homonymen in der Übersetzung (siehe auch Video oben).
- Das Ausgabeformat kann genau auf einen bestimmten Use Case hin optimiert werden. YAML hat sich in unseren aktuellen Forschungen als effektives Format für LLMs gezeigt, weshalb unser MCP-Server YAML an die LLMs übergibt.
- Der Zugriff ist in Echtzeit und nicht auf statische, hochgeladene Daten.
- Die gesamte Konfiguration kann durch die Terminologie- oder Sprachabteilung erfolgen, was die interdisziplinäre Zusammenarbeit und eine effiziente Arbeitsteilung ermöglicht.
Darüber hinaus vereinfacht die Anbindung via Quickterm MCP-Server die Umsetzung von TAG signifikant:
- Die Firmen-IT muss keine eigenen Clients programmieren. Mit anderen Ansätzen wie Function Calling oder Pipelines, muss de facto für jedes anzubindende Tool erneut ein Client entwickelt werden. Mit MCP ist einmal ein Standard geschaffen, auf den alle Use Cases und Applikationen zugreifen können.
- Das LLM ruft nativ das richtige MCP-Tool auf. Dieses ist mit einem Retrieval-Profil in Quickterm verknüpft, das wiederum die Suche, Ausgabedaten, Ausgabeformat etc. steuert. Retourniert werden genau die Kontexte, die das LLM in dem jeweiligen Use Case benötigt.
- TAG mit MCP ermöglicht eine extrem effiziente Umsetzung von TAG. Da die Linguist:innen die Konfiguration auf der Sprachseite erledigen können, muss die IT lediglich den MCP-Server mit URL und Authentifizierungs-Token anbinden.
Wie können Sie das angehen?
Falls Sie noch keinen Kontakt zu Ihrer Unternehmens-IT bezüglich Terminologie für KI und (Terminology-) Augmented Generation oder Fine-Tuning von LLMs mit Terminologiedaten haben, empfehlen wir allen Terminologieverantwortlichen, sich unbedingt umzuhören und die richtigen Ansprechpersonen zu finden. Oft sind KI-Projekte sehr dezentral oder übergreifend angesiedelt und Projektverantwortliche sich der potenziell bestehenden Terminologie gar nicht bewusst, ganz zu schweigen von den ungemein wertvollen, weil strukturierten, abgestimmten und mehrsprachigen Sprachdaten.
Dabei ist das Wichtigste, was Ihre internen KI-Projekte benötigen, genau das: zuverlässige Daten und Informationen in strukturierter Form über die Produkte, Prozesse usw. im Unternehmen. Und genau diese Informationen liegen in der Termbank in Form von Konzepten oder Begriffen vor. Meistens ist der Vorteil von TAG einer KI-Projektleitung auch einfach zu vermitteln. Gerne können Sie die Vorteile aus diesem Blog anführen. Und in der Regel sind die KI-Entwickler:innen auch begeistert davon, dass es bereits einen fertigen Ansatz im MCP-Server für Quickterm gibt, den sie lediglich einbinden müssen.
Die KI-Abteilung spart mit MCP massiv an Implementierungsaufwand und kommt signifikant schneller und zuverlässiger an ihr Ziel. Und die eigentliche Konfiguration der TAG-Funktionen übernehmen ja Sie mit Ihrer Terminologie- oder Sprachabteilung. Warum sollte die Projektleitung also nicht mit Ihnen sprechen wollen?
Wenn Sie vor diesen Gesprächen noch Ihr Wissen bezüglich KI auf den neuesten Stand bringen möchten, so bieten wir dafür maßgeschneiderte öffentliche oder auch Inhouse-Workshops an. In wenigen Stunden machen diese Sie fit für TAG, RAG, Prompting, und vermitteln, warum Terminologie so hilfreich bei Unternehmens-KI ist.
Zusätzlich bieten wir auch einen TAG Discovery Workshop an und nehmen gerne auch an Ihren ersten internen Gesprächen teil.
Fazit: TAG und MCP sind echte Gamechanger
Aus unserer Sicht ist TAG via MCP ein echter Gamechanger. Diese Technologie ermöglicht es uns, den wertvollen Datenbestand unserer Terminologie im Handumdrehen dem gesamten Unternehmen zugänglich zu machen: Transparent im Hintergrund eingebunden in alle erdenklichen KI-Anwendungen. Damit wird Terminologie zu einem zentralen Asset im Unternehmen, was nicht nur dem Standing des Terminologiethemas im Unternehmen hilft, sondern auch für das Business Modell Terminologie einen deutlich höheren Return on Investment bringt. Und natürlich bringt es die Unternehmens-KI einen beachtlichen Schritt weiter in Richtung Zuverlässigkeit und Produktivität.
Weiterführende Literatur und Studien
- Klaus Fleischmann, Christian Lang (2025): Terminologie in der KI. Wie mit Terminologie der Output von LLMs und GenAI optimiert werden kann
- Anna Lackner, Alena Vega-Wilson and Christian Lang: Terminology Augmented Generation: A Systematic Review of Terminology Formats for In-Context Learning in LLMs
- Giorgio Maria Di Nunzio: Terminology-Augmented Generation (TAG): Foundations, Use Cases, and Evaluation Paths
- Karolina Suchowolec: TermRAG, TAG & Co. – viele Namen, vielfältige Einsatzmöglichkeiten
