

Generative AI combined with either large language models (LLMs) or small language models (SLMs) [1] has become an integral part of many professional communication and documentation departments, even though it only appeared on the scene a few years ago. With generative AI increasing the efficiency and productivity of copywriters, technical writers, and other content creators, it is increasingly being used to facilitate the creation and translation of information products.
The contents at a glance:
Nevertheless, technical documentation must still meet other requirements regardless of any efficiency considerations, such as comprehensibility and legal certainty of the information products—whether AI is used or not. This often goes hand in hand with other quality requirements such as recognizability and consistency in corporate communications [2].
If we narrow our focus down to terminology in particular, the reasons for establishing standardized terminology processes in companies often relate to the quality benefits that arise from the consistent usage of terminology and thus greater text comprehensibility [3]. However, it is well known that the lack of terminological consistency and the use of non-company-specific terms is one of the biggest weaknesses of AI-generated texts when working with generic LLMs [4, 5].
LLMs and terminology requirements
LLMs can be 'forced' to use certain terminology in a number of ways [4]. In simple cases, the terminology can be stipulated by the user in the prompt at the end of their actual query by just inserting all the information from a terminology database as plain text. The LLM then processes this terminological information together with the actual query and decides which parts of the terminology database are relevant for its answer.
Similarly, some AI chatbots can also be provided with additional information in a file: in other words, the user can export the entire terminology database and uploaded it to the chat. Alternatively, terminological instructions can also be stored in the system prompts.
All these methods are user-friendly and technically easy to implement, although they do have their disadvantages. While terminology databases can contain thousands of concepts with detailed additional data such as definitions, designations, and usage status, LLMs can only process a limited amount of information (measured in so-called "tokens"). Referred to as the "window", exceeding this limit causes the LLM to omit the extra terminology specifications and conversation details, which ultimately leads to an unsatisfactory result [6]. Terminological consistency is one of the qualities that can be negatively impacted, even though the correct terminology was actually provided to the model.
Another disadvantage of these more simple methods is that the LLM itself has to decide which parts of the terminology database are relevant for answering the current query. Practical experience has shown that the LLM often makes the wrong decision here. In addition to these two problems, companies must be alive to the dangers of feeding commercially sensitive or copyright-protected data into an LLM.
Terminological data and RAG
The so-called RAG technique (Retrieval-Augmented Generation) has been developed in recent years to overcome the problems mentioned above when linking external data to an LLM [7, 8]. The basic idea is to pre-select only those sections from the available documentation (known as a knowledge base) that are actually relevant before any further processing takes place in the LLM. Relevant sections can be selected using different information retrieval techniques depending on the application scenario and the nature of the documents in the knowledge base. This means that the LLM only has to process as much information as necessary, which can largely counteract the "window" problem and protect sensitive data at the same time.
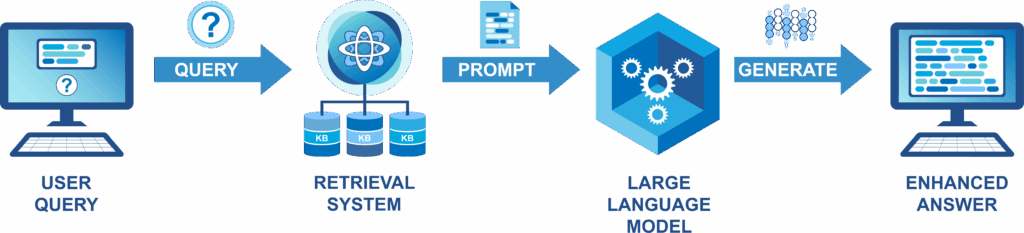
Yet the LLM can benefit from much more than just information on which terms to use. Within the terminology community, the use of terminology databases for knowledge management has been a topic of hefty discussion for many years now [3, 4, 9]. Linking terminological data to LLMs using RAG can also unlock further benefits thanks to the additional information that these databases contain: content such as term definitions and other useful details enables the company-wide understanding of concepts and terms to be fed into the LLM. In this way, an LLM-based, terminology-supported chatbot could play an important role in the transfer and exchange of knowledge in both internal and external company communications.
The good news is that using terminology databases as a knowledge base for RAG is already providing good results without the terminology database needing to contain an explicit term system or be available as formal knowledge graphs [6, 10]. Existing terminology databases already create added value for LLMs if they follow the simple concept-oriented structure. However, academic studies have shown that explicit concept relationships hold even more potential for LLMs and therefore for further application scenarios of terminology databases [11].
TermRAG, TAG & Co.—Implementation
These and other potential applications for connecting terminology databases to LLMs using a RAG pipeline are currently being widely discussed and tested in theory and in practice [5, 6, 10]. It is a topic that has even found its way into terminology training [12], where the associated technology often has a number of different names in the terminology community (such as TermRAG [12], TAG [6], or M-RAG [13]). While we cannot examine the content of these discussions in any great detail here (such as the favorable data format, the appropriate retrieval technique, or prompt engineering), we will outline the current technical possibilities.
The technical implementation options for TermRAG are developing at a rapid pace, as is the industry as a whole. Until now, TermRAG has often been designed as a standalone solution based on the implementation options of a general, non-terminology-specific RAG pipeline. This means that a solution is needed within an organization's own IT infrastructure with self-programmed technologies [10]—together with all the inherent advantages and disadvantages that this entails. User-friendly RAG infrastructures that do not require any programming knowledge and which can also be used for special TermRAG applications are increasingly being made available for research purposes [14, 15]. The first commercial solutions that offer direct integration with existing terminology management systems [6, 13] are also starting to be released.
Conclusion
TermRAG is a topic of hot discussion in the terminology community, and rightly so. However, RAG solutions for commercial users can be thought of more broadly, as the knowledge base can contain different document types for different tasks. Terminology databases can therefore be seen as a building block in a more complex company-internal RAG infrastructure.
Studies and practical trials confirm that existing, concept-oriented terminology databases also prove their worth in the context of generative AI. They offer a high reusability value and improve the quality of text generation and translation in technical documentation. Terminology databases therefore continue to make an important contribution to precise, efficient, and legally compliant technical communication.
Further Reading
- Belcak, Peter; Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, Pavlo Molchanov (2025): "Small Language Models are the Future of Agentic AI." Preprint under review, [v1] Mon, 2 Jun 2025, https://arxiv.org/abs/2506.02153
- DIN EN IEC/IEEE 82079-1 (VDE 0039-1) (2021): Erstellen von Gebrauchsanleitungen– Gliederung, Inhalt und Darstellung – Teil 1: Allgemeine Grundsätze und ausführliche Anforderungen. Berlin: Beuth
- Deutscher Terminologie-Tag e.V. (2014): Terminologiearbeit: Best-Practices 2.0 (Ordner). Köln: Deutscher Terminologie-Tag
- Massion, François (2024): "Terminology in the Age of AI: The Transformation of Terminology Theory and Practice." Journal of Translation Studies 4 [1]: 67–94
- Hamm, Julian (2025): "Terminologische Konsistenz und generative KI – ein Perfect Match? Produktiver Einsatz von Sprachmodellen im Terminologiemanagement und beim Post-Editing." Petra Drewer, Felix Mayer, Donatella Pulitano (eds.): Terminologie in der KI – KI in der Terminologie. Akten des Symposions Worms, 27.–29. März 2025. München/Karlsruhe/Bern: Deutscher Terminologie-Tag e.V., 151–163
- Fleischmann, Klaus; Christian Lang (2025): "Terminologie in der KI. Wie mit Terminologie der Output von LLMs und GenAI optimiert werden kann." Petra Drewer, Felix Mayer, Donatella Pulitano (eds.): Terminologie in der KI – KI in der Terminologie. Akten des Symposions Worms, 27.–29. März 2025. München/Karlsruhe/Bern: Deutscher Terminologie-Tag e.V., 83–95
- Lewis, Patrick; Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela (2021): “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.“ [v4] Mon, 12 Apr 2021, https://arxiv.org/abs/2005.11401
- Gao, Yunfan; Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, Haofen Wang (2024): “Retrieval-Augmented Generation for Large Language Models: A Survey.” [v5] Wed, 27 Mar 2024, https://arxiv.org/abs/2312.10997
- Drewer, Petra; Donatella Pulitano, François Massion (2017): "Terminologie im Zeitalter der Künstlichen Intelligenz (KI)." edition 13 [2]: 5–10
- Lang, Christian; Roman Schneider, Ngoc Duyen Tanja Tu (2024): "Automatic Question Answering for the Linguistic Domain – An Evaluation of LLM Knowledge Base Extension with RAG." Amon Rapp, Luigi Di Caro, Farid Meziane, Vijayan Sugumaran (eds.): Natural Language Processing and Information Systems. Cham: Springer, 161–171
- Remy, François; Kris Demuynck, Thomas Demeester (2023): "Automatic Glossary of Clinical Terminology: a Large-Scale Dictionary of Biomedical Definitions Generated from Ontological Knowledge." The 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks. Toronto: Association for Computational Linguistics, 265–272
- "TermRAG 4 SafeAI – Verlässlichkeit und Rechtssicherheit KI-generierter Inhalte durch Retrieval Augmented Generation. Technische und didaktische Rahmenbedingungen für die Lehre in den Geistes- und Sozialwissenschaften." TH Köln, Projektwebseite: https://www.th-koeln.de/informations-und-kommunikationswissenschaften/verlaesslichkeit-und-rechtssicherheit-ki-generierter-inhalte-durch-retrieval-augmented-generation-rag_123037.php (accessed on 8 July 2025)
- Hummel, Jochen (2023): "M-RAG: Retrieval Augmented Generation Goes Global Revolutionizing Global Customer Support: The Power of Multilingual Retrieval Augmented Generation (M-RAG)." 05.12.2023, https://coreon.com/2023/12/05/m-rag-goes-global/ (accessed on 8 July 2025)
- "Arcana/RAG.", Gesellschaft für Wissenschaftliche Datenverarbeitung mbH Göttingen (GWDG), service documentation: https://docs.hpc.gwdg.de/services/arcana/index.html (accessed on 8 July 2025)
- "Open Source-KI.nrw. Quelloffene KI. Lokal bereitgestellt." (2025) project website: https://www.oski.nrw (accessed on 8 July 2025)
