

Generative KI mit großen Sprachmodellen (Large Language Models, LLMs) und ihren kleineren "Verwandten" (Small Language Models, SLMs) [1] ist aus der professionellen Kommunikation nicht mehr wegzudenken, obwohl sie erst vor wenigen Jahren eingeführt wurde. Generative KI erhöht die Effizienz und Produktivität der Arbeitsprozesse und wird deshalb auch zunehmend in der Technischen Dokumentation eingesetzt, um das Schreiben und Übersetzen von Informationsprodukten zu erleichtern.
Der Inhalt im Überblick:
Dennoch muss die Technische Dokumentation – mit oder ohne KI-Einsatz – neben dem Effizienzgedanken nach wie vor weitere Anforderungen wie Verständlichkeit und Rechtsicherheit der Informationsprodukte erfüllen. Dies geht häufig mit weiteren Qualitätsanforderungen wie Wiedererkennbarkeit und Kontinuität der Unternehmenskommunikation einher [2].
Engt man den Fokus auf Terminologie ein, betreffen die Gründe für die Etablierung von Terminologieprozessen in Unternehmen oft Qualitätsvorteile, die sich aus konsistenter Terminologieverwendung und somit gesteigerter Textverständlichkeit ergeben [3]. Bekanntermaßen sind aber die mangelnde Konsistenz der Terminologie und die Verwendung nicht unternehmensspezifischer Benennungen eine der größten Schwächen von KI-generierten Texten, wenn mit generischen LLMs gearbeitet wird [4, 5].
LLMs und terminologische Vorgaben
Terminologievorgaben können LLMs auf verschiedene Weisen bereitgestellt werden [4]. In einfachen Fällen können sie Teil des Prompts – also der Anfrage – sein, den Nutzende eingeben. Der Nutzende kann beispielsweise am Ende seiner eigentlichen Anfrage alle Informationen aus einer Terminologiedatenbank als einfachen Text einsetzen. Das LLM verarbeitet dann diese terminologischen Informationen zusammen mit der eigentlichen Anfrage und entscheidet, welche Teile aus der Terminologiedatenbank für die Beantwortung der Anfrage relevant sind.
Ähnlich können bei einigen KI-Chatbots Zusatzinformationen auch in einer Datei bereitgestellt werden. Somit kann die komplette Terminologiedatenbank exportiert und im Chat hochgeladen werden. Weitere Möglichkeiten umfassen beispielsweise das Hinterlegen von Terminologievorgaben in sogenannten System-Prompts.
Die geschilderten Methoden sind benutzungsfreundlich, da sie inzwischen technisch leicht umsetzbar sind; sie bringen jedoch einige Nachteile mit sich. Zum einen können Terminologiedatenbanken tausende Begriffe mit zahlreichen weiteren Angaben wie beispielsweise Definitionen, Benennungen und Verwendungsstatus umfassen. LLMs können jedoch nur eine begrenzte Anzahl an Informationen (in sogenannten "Tokens" gemessen) verarbeiten. Diese Begrenzung wird als "Fenster" bezeichnet; wird sie überschritten, lässt das LLM die Terminologievorgaben und Konversationsdetails aus, was zu einem qualitativ unbefriedigenden Ergebnis führt [6]. So kann darunter die terminologische Konsistenz der Texte leiden, obwohl die Vorgaben dem Modell eigentlich bereitgestellt wurden.
Ein weiterer Nachteil der geschilderten Methoden besteht darin, dass dabei das LLM selbst entscheiden muss, welche Teile der Terminologiedatenbank für die aktuelle Anfrage relevant sind. Praxiserfahrungen zeigen, dass das LLM mit der Entscheidung häufig falsch liegt.
Neben diesen beiden Problemen sind aus Sicht von Unternehmen die Fragen des Schutzes von unternehmenssensiblen oder urheberrechtlich geschützten Daten, die in ein LLM eingespeist werden, nicht zu vernachlässigen.
Terminologische Daten und RAG
Um die genannten Probleme bei der Anbindung von externen Daten an LLMs zu bewältigen, wurde in den letzten Jahren die sogenannte RAG-Technik (Retrieval-Augmented Generation) entwickelt [7, 8]. Die Grundidee ist es, relevante Abschnitte aus einer Dokumentsammlung, also einer sogenannten Wissensbasis, vorab zu selektieren, bevor sie vom LLM weiterverarbeitet werden. Die Auswahl von relevanten Abschnitten kann je nach Anwendungsszenario und Beschaffenheit der Dokumente in der Wissensbasis mit unterschiedlichen Information-Retrieval-Techniken erfolgen. Dadurch muss das LLM nur so viele Informationen wie nötig verarbeiten, was die "Fenster"-Problematik minimieren und gleichzeitig sensible Daten schützen kann.
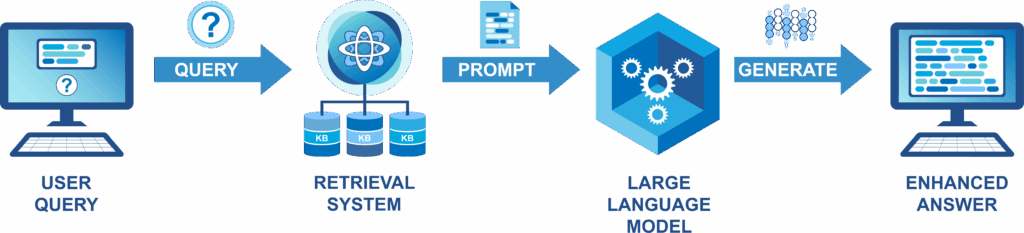
Das LLM kann aber nicht nur von Informationen zu Benennungsverwendung profitieren. In der terminologischen Community ist die Nutzung von Terminologiedatenbanken im Kontext von Wissensmanagement ein seit Jahren diskutiertes Thema [3, 4, 9]. Auch das kann die Anbindung terminologischer Daten an LLMs mittels RAG leisten: Dank hinterlegten Begriffsdefinitionen und weiteren Angaben kann das unternehmensweite Verständnis von Begriffen und Benennungen an das LLM weitergegeben werden. Auf diese Weise kann beispielsweise ein LLM-basierter, terminologiegestützter Chatbot eine wichtige Rolle bei Weitergabe und Austausch von Wissen in der unternehmensinternen und -externen Kommunikation spielen. Die gute Nachricht dabei ist: Terminologiedatenbanken als Wissensbasis für RAG liefern bereits gute Ergebnisse, ohne dass darin ein Begriffssystem explizit enthalten sein muss oder sie als formal beschriebene Wissensgraphen vorliegen [6, 10]. Bestehende Terminologiedatenbanken schaffen bereits einen Mehrwert für LLMs, wenn sie der einfachen begriffsorientierten Struktur folgen. Wissenschaftliche Studien zeigen allerdings, dass explizit hinterlegte Begriffsbeziehungen noch mehr Potenzial für LLMs und daher für weitere Anwendungsszenarien von Terminologiedatenbanken bergen [11].
TermRAG, TAG & Co. – Implementierung
Diese und weitere Anwendungsszenarien für die Anbindung von Terminologiedatenbanken an LLMs mittels einer RAG-Pipeline werden in der Forschung und Praxis aktuell diskutiert [5, 6, 10]. Das Thema hat auch Einzug in die terminologische Ausbildung gehalten [12]. Dabei wird die Technik in der terminologischen Community unterschiedlich bezeichnet, z.B. als TermRAG [12], TAG [6] oder M-RAG [13]. In diesem Blog-Beitrag kann auf viele Details der aktuellen Diskussion wie das günstige Datenformat, die passende Retrieval-Technik oder das Prompt-Engineering nicht eingegangen werden kann, es sollen aber abschließend noch die aktuellen technischen Möglichkeiten skizziert werden.
Die technischen Implementierungsmöglichkeiten für TermRAG entwickeln sich, wie die gesamte Branche, mit rasanter Geschwindigkeit. Bisher wird TermRAG häufig als individuelle Lösung konzipiert, die auf Umsetzungsmöglichkeiten einer allgemeinen, nicht terminologiespezifischen RAG-Pipeline basiert. Dies bedeutet die Notwendigkeit einer Lösung innerhalb eigener IT-Infrastruktur mit selbst programmierten Techniken [10], was mit allen Vor- und Nachteilen solcher Lösungen einhergeht. Für die Forschung werden zunehmend auch benutzungsfreundliche RAG-Infrastrukturen bereitgestellt, die keine Programmierkenntnisse erfordern und auch für spezielle TermRAG-Anwendungen genutzt werden können [14, 15]. Für Unternehmen gibt es auch erste kommerzielle Lösungen, die eine direkte Integration mit bestehenden Terminologieverwaltungssystemen bieten [6, 13].
Fazit
TermRAG ist ein Thema, das die terminologische Community derzeit zu Recht beschäftigt. RAG-Lösungen für Unternehmen können aber breiter gedacht werden, da die Wissensbasis unterschiedliche Dokumenttypen für unterschiedliche Aufgaben enthalten kann. Terminologiedatenbanken können daher als ein Baustein in einer komplexeren unternehmensinternen RAG-Infrastruktur gesehen werden.
Studien und Praxisprojekte bestätigen: Bestehende, begriffsorientierte Terminologiedatenbanken bewähren sich auch im Kontext von generativer KI. Sie bieten hohen Wiederverwendungswert und verbessern die Textgenerierung und -übersetzung in der Technischen Dokumentation. So leisten Terminologiedatenbanken weiterhin einen wichtigen Beitrag zur präzisen, effizienten und rechtssicheren Technischen Kommunikation.
Zum Nachlesen
- Belcak, Peter; Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, Pavlo Molchanov (2025): "Small Language Models are the Future of Agentic AI." Preprint under review, [v1] Mon, 2 Jun 2025, https://arxiv.org/abs/2506.02153
- DIN EN IEC/IEEE 82079-1 (VDE 0039-1) (2021): Erstellen von Gebrauchsanleitungen– Gliederung, Inhalt und Darstellung – Teil 1: Allgemeine Grundsätze und ausführliche Anforderungen. Berlin: Beuth
- Deutscher Terminologie-Tag e.V. (2014): Terminologiearbeit: Best-Practices 2.0 (Ordner). Köln: Deutscher Terminologie-Tag
- Massion, François (2024): "Terminology in the Age of AI: The Transformation of Terminology Theory and Practice." Journal of Translation Studies 4 [1]: 67–94
- Hamm, Julian (2025): "Terminologische Konsistenz und generative KI – ein Perfect Match? Produktiver Einsatz von Sprachmodellen im Terminologiemanagement und beim Post-Editing." Petra Drewer, Felix Mayer, Donatella Pulitano (Hrsg.): Terminologie in der KI – KI in der Terminologie. Akten des Symposions Worms, 27.–29. März 2025. München/Karlsruhe/Bern: Deutscher Terminologie-Tag e.V., 151–163
- Fleischmann, Klaus; Christian Lang (2025): "Terminologie in der KI. Wie mit Terminologie der Output von LLMs und GenAI optimiert werden kann." Petra Drewer, Felix Mayer, Donatella Pulitano (Hrsg.): Terminologie in der KI – KI in der Terminologie. Akten des Symposions Worms, 27.–29. März 2025. München/Karlsruhe/Bern: Deutscher Terminologie-Tag e.V., 83–95
- Lewis, Patrick; Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela (2021): “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.“ [v4] Mon, 12 Apr 2021, https://arxiv.org/abs/2005.11401
- Gao, Yunfan; Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, Haofen Wang (2024): “Retrieval-Augmented Generation for Large Language Models: A Survey.” [v5] Wed, 27 Mar 2024, https://arxiv.org/abs/2312.10997
- Drewer, Petra; Donatella Pulitano, François Massion (2017): "Terminologie im Zeitalter der Künstlichen Intelligenz (KI)." edition 13 [2]: 5–10
- Lang, Christian; Roman Schneider, Ngoc Duyen Tanja Tu (2024): "Automatic Question Answering for the Linguistic Domain – An Evaluation of LLM Knowledge Base Extension with RAG." Amon Rapp, Luigi Di Caro, Farid Meziane, Vijayan Sugumaran (Hrsg.): Natural Language Processing and Information Systems. Cham: Springer, 161–171
- Remy, François; Kris Demuynck, Thomas Demeester (2023): "Automatic Glossary of Clinical Terminology: a Large-Scale Dictionary of Biomedical Definitions Generated from Ontological Knowledge." The 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks. Toronto: Association for Computational Linguistics, 265–272
- "TermRAG 4 SafeAI – Verlässlichkeit und Rechtssicherheit KI-generierter Inhalte durch Retrieval Augmented Generation. Technische und didaktische Rahmenbedingungen für die Lehre in den Geistes- und Sozialwissenschaften." TH Köln, Projektwebseite: https://www.th-koeln.de/informations-und-kommunikationswissenschaften/verlaesslichkeit-und-rechtssicherheit-ki-generierter-inhalte-durch-retrieval-augmented-generation-rag_123037.php (Zugriff: 08.07.2025)
- Hummel, Jochen (2023): "M-RAG: Retrieval Augmented Generation Goes Global Revolutionizing Global Customer Support: The Power of Multilingual Retrieval Augmented Generation (M-RAG)." 05.12.2023, https://coreon.com/2023/12/05/m-rag-goes-global/ (Zugriff 08.07.2025)
- "Arcana/RAG.", Gesellschaft für Wissenschaftliche Datenverarbeitung mbH Göttingen (GWDG), Servicedokumentation: https://docs.hpc.gwdg.de/services/arcana/index.html (Zugriff: 08.07.2025)
- "Open Source-KI.nrw. Quelloffene KI. Lokal bereitgestellt." (2025) Projektwebseite: https://www.oski.nrw (Zugriff: 08.07.2025)
